近日,SuperCLUE-Fin(SC-Fin)中文原生金融大模型测评基准正式发布,对国内外金融大模型的发展水平进行了全方位、多角度评估。智谱AI自主研发的新一代基座大模型GLM-4脱颖而出,跻身国内首批获得A级评价的模型之列,依据模型表现,GLM-4位列第一梯队,在国内大模型中排名第一。
本次测评涵盖金融知识百科、金融理解认知、金融数理计算、合规与风险管理、投研应用以及投顾应用六大领域共计二十五项细分任务。测评人员通过模拟真实用户与模型互动,采用单轮问答、多轮交互等多种形式,对模型的专业知识掌握、逻辑分析能力、语言表达清晰度、计算效率以及企业综合业务分析、风险预测与管控等能力进行了详尽检验。
测评结果显示,在六类应用场景的二十五项细分任务中,GLM-4斩获了一项A+及多项A级评价,彰显出其在国内金融智能解决方案领域的领先技术水平与广泛应用潜能。
总等级榜单
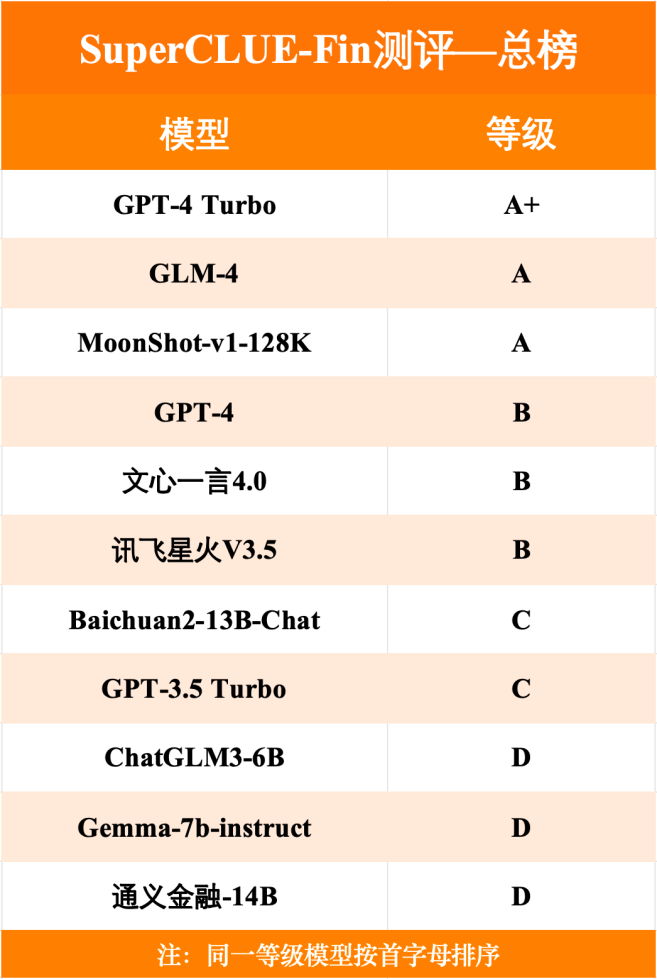
任务大类等级榜单
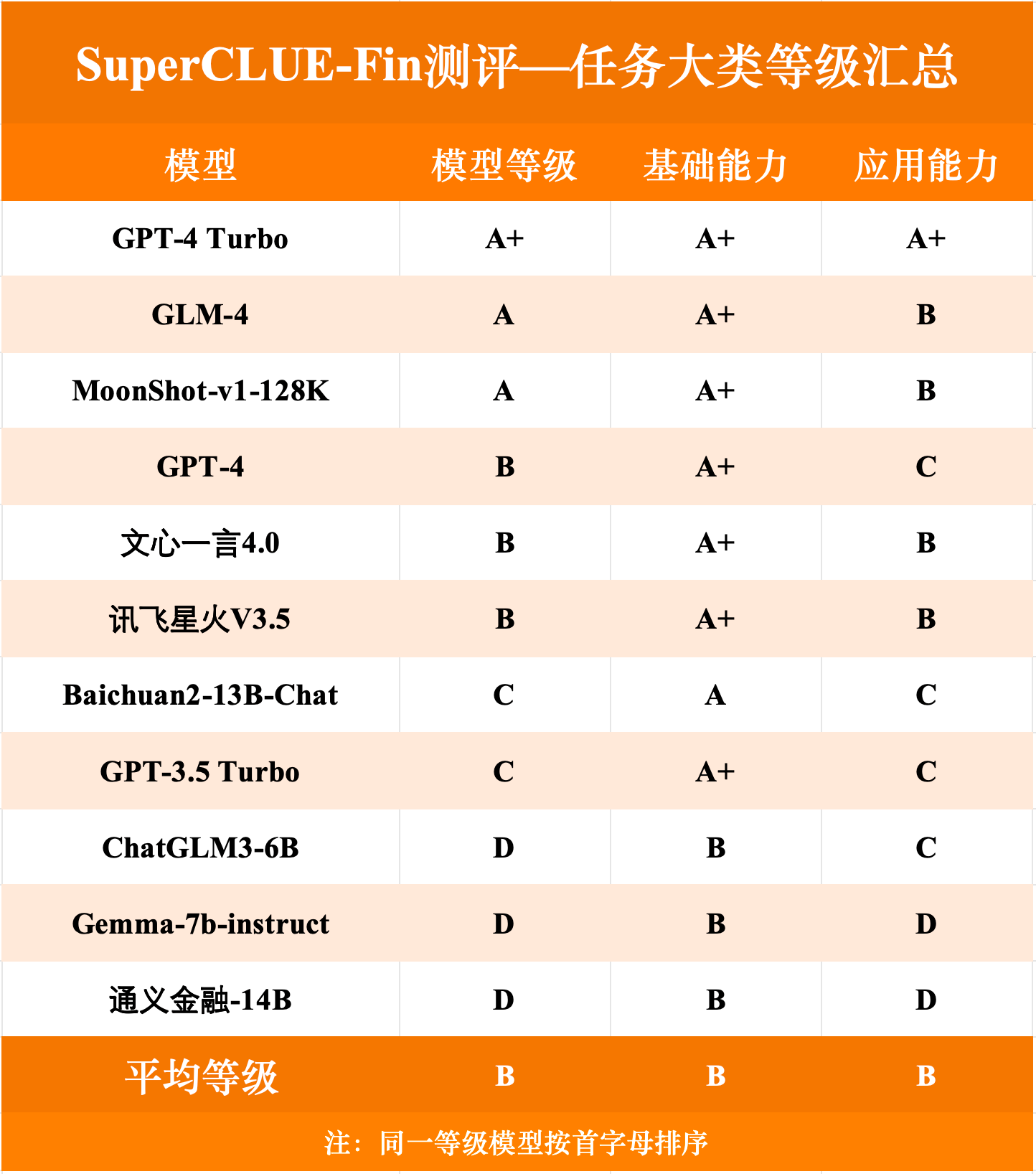
各任务等级榜单
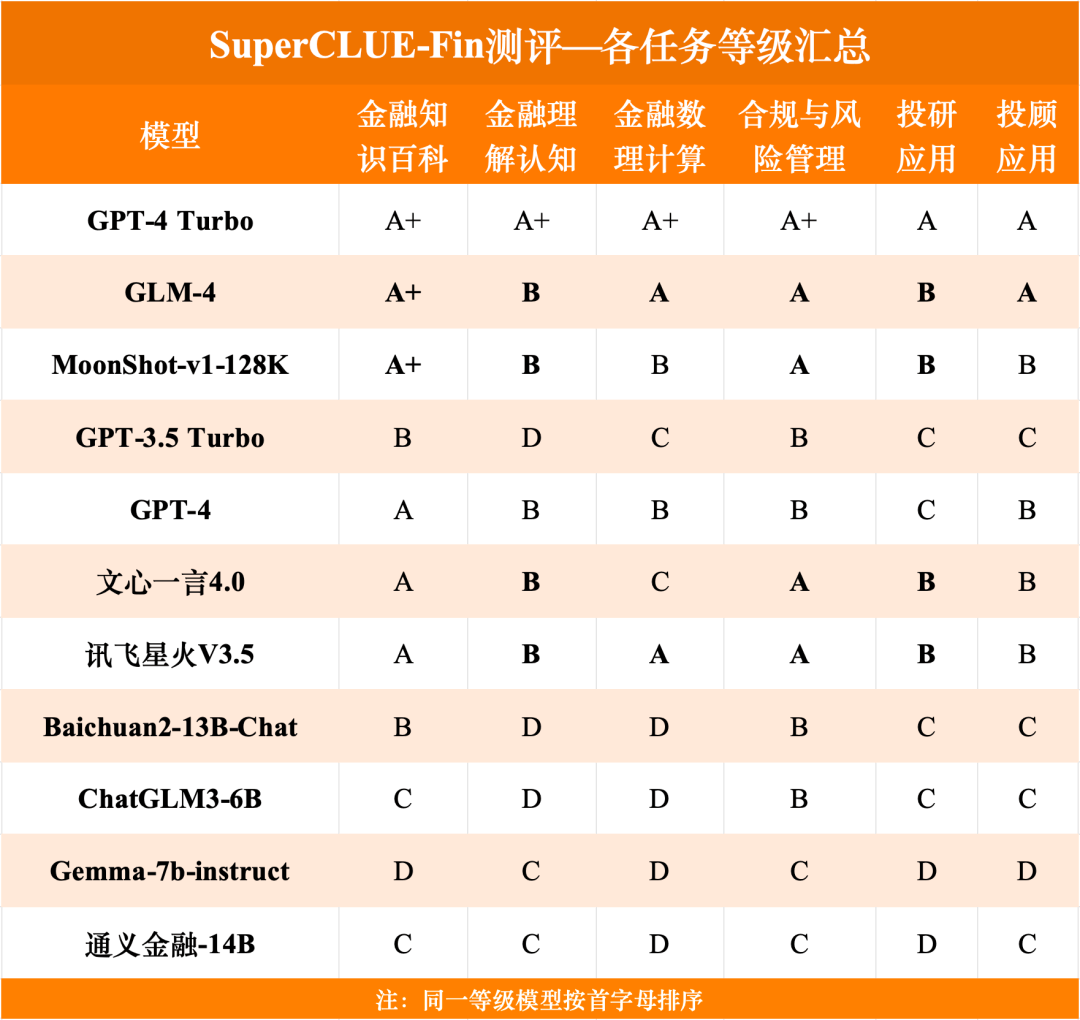
金融知识百科榜单
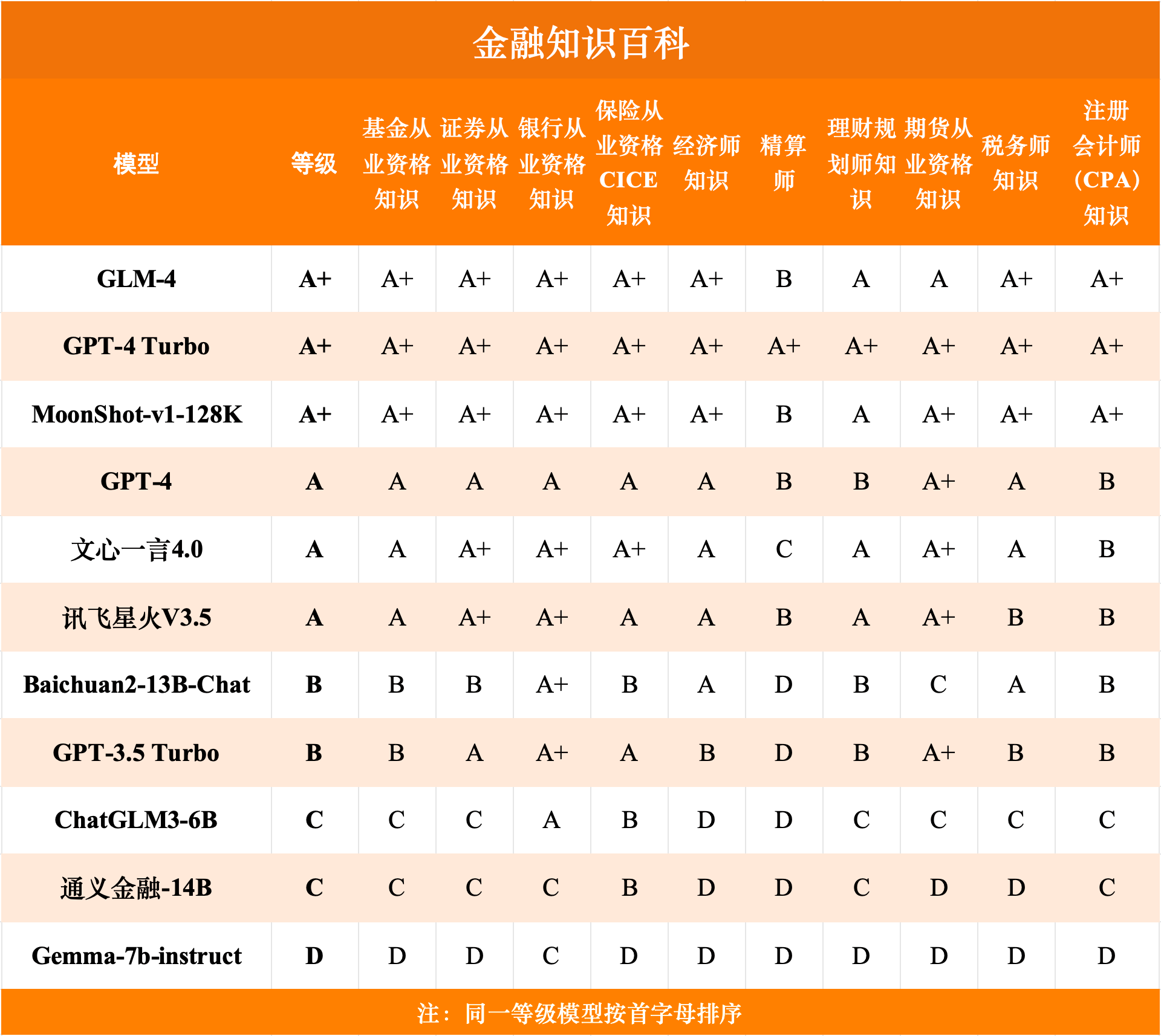
金融数理计算榜单
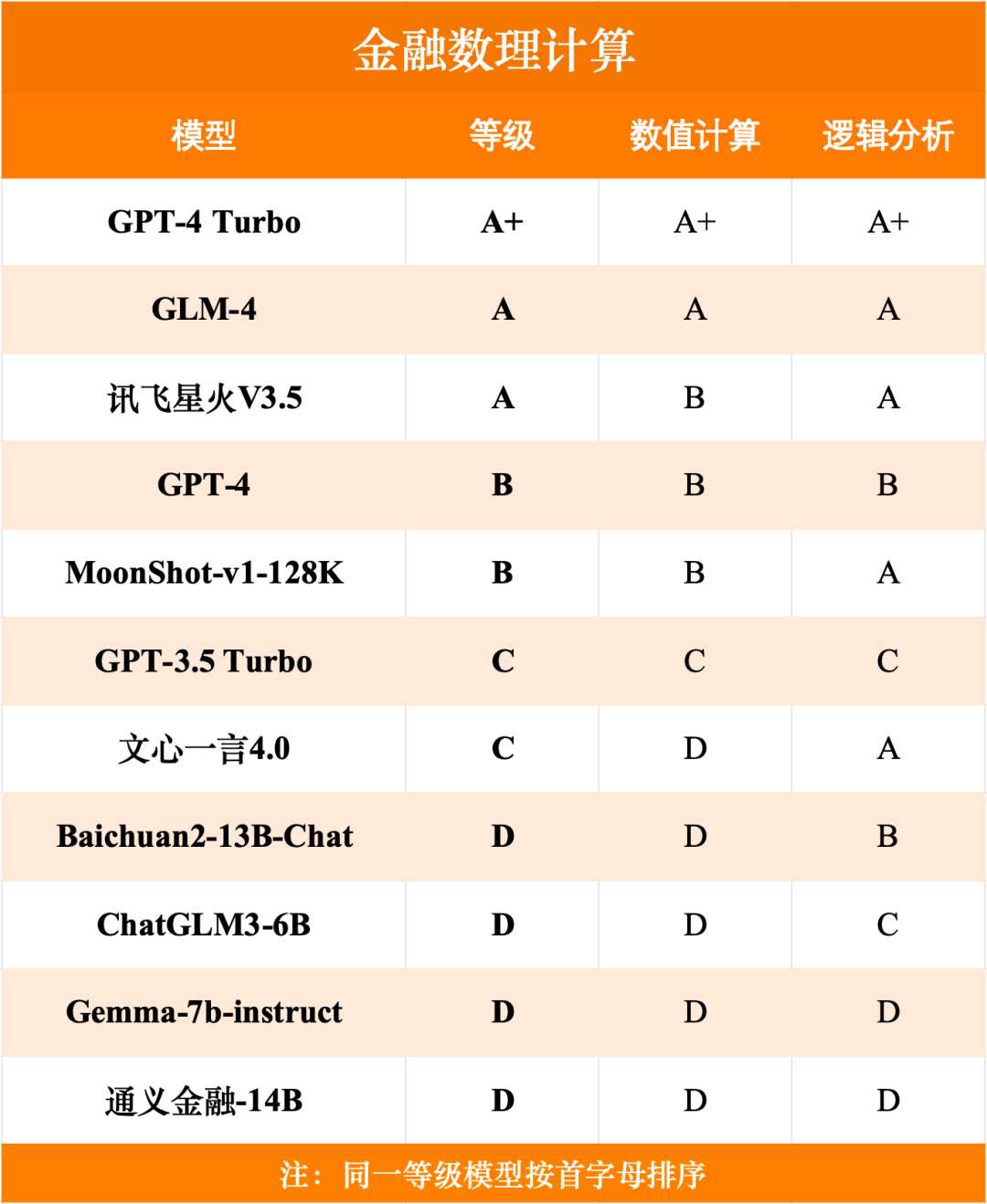
合规与风险管理榜单
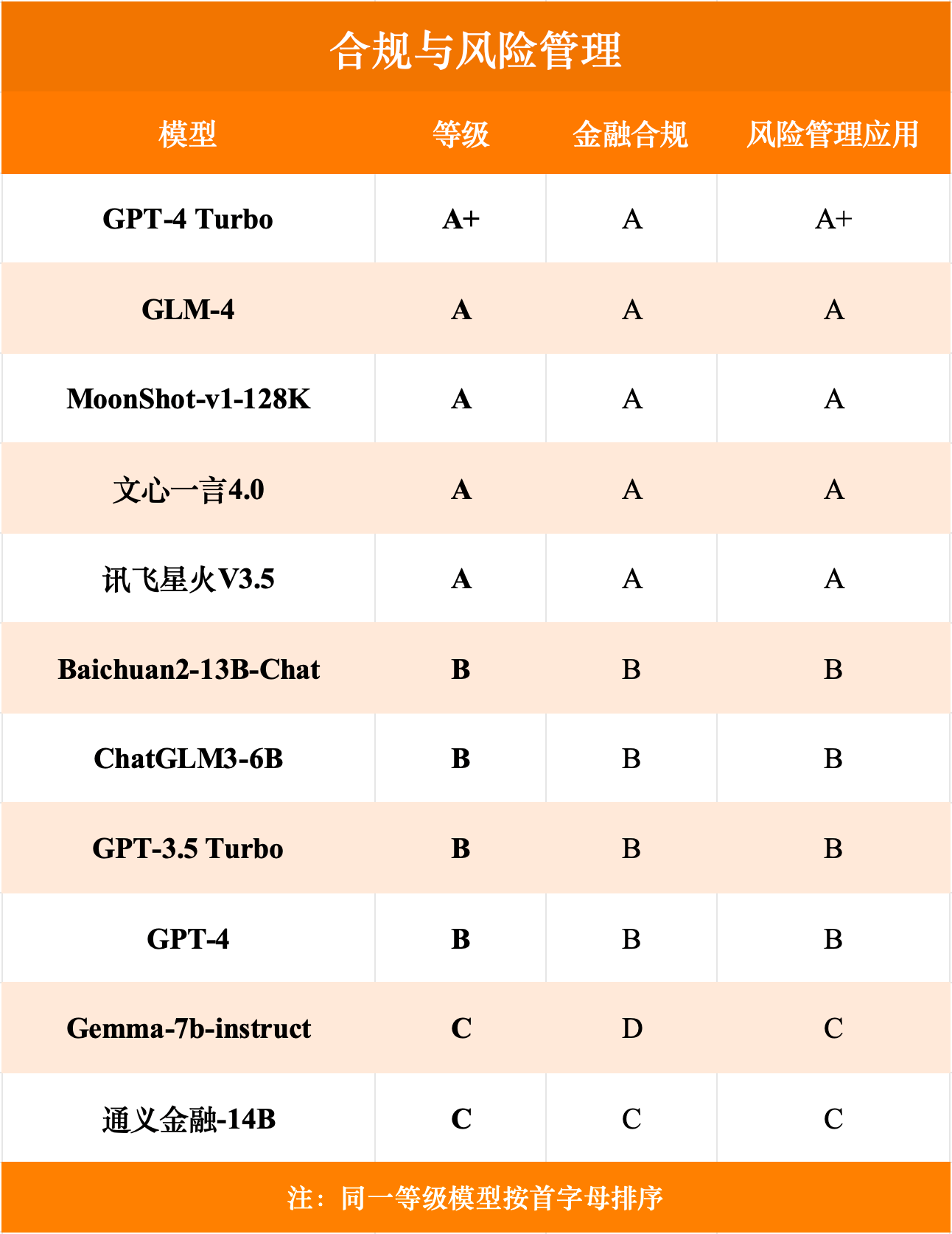
投顾应用榜单
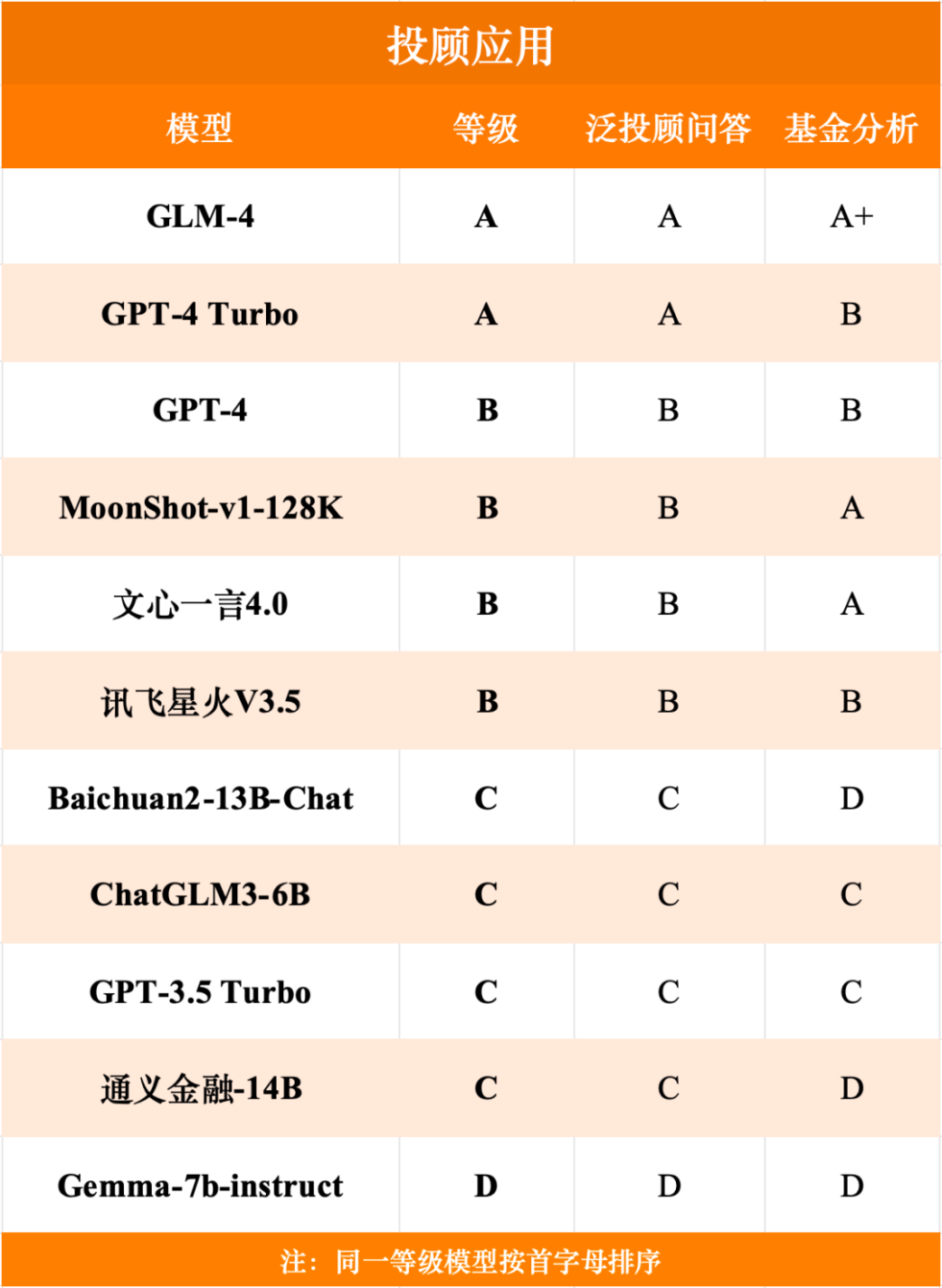
根据测评榜单,从模型等级角度看,目前仅有GPT-4 Turbo在总成绩中达到了A+的级别,国内的GLM-4与MoonShot-v1-128k等级达到A。从六类具体任务得分角度来看,各模型各类任务得分较为均衡,其中GLM-4表现较为优异,获得了一项A+、三项A与两项B,且与GPT-4 Turbo各任务等级相差较小。
测评结论指出,从金融大模型综合能力上看,国内外头部模型差距较小,体现了国内大模型在金融领域综合能力上有一定的竞争力。在本次金融测评中,依据模型表现,GLM-4位列第一梯队,其等级为A,仅低于GPT-4 Turbo,国内排名第一。从金融大模型专项能力上来看,真正实现大语言模型在金融领域的高度专业化水准仍然有一定的距离,提高金融大模型数据库质量、完善模型对于金融学问题的解释标准(尤其是依据国内标准),亦或为提升金融大模型性能的关键路径。
近日,SuperCLUE-Fin(SC-Fin)中文原生金融大模型测评基准正式发布,对国内外金融大模型的发展水平进行了全方位、多角度评估。智谱AI自主研发的新一代基座大模型GLM-4脱颖而出,跻身国内首批获得A级评价的模型之列,依据模型表现,GLM-4位列第一梯队,在国内大模型中排名第一。
本次测评涵盖金融知识百科、金融理解认知、金融数理计算、合规与风险管理、投研应用以及投顾应用六大领域共计二十五项细分任务。测评人员通过模拟真实用户与模型互动,采用单轮问答、多轮交互等多种形式,对模型的专业知识掌握、逻辑分析能力、语言表达清晰度、计算效率以及企业综合业务分析、风险预测与管控等能力进行了详尽检验。
测评结果显示,在六类应用场景的二十五项细分任务中,GLM-4斩获了一项A+及多项A级评价,彰显出其在国内金融智能解决方案领域的领先技术水平与广泛应用潜能。
总等级榜单
任务大类等级榜单
各任务等级榜单
金融知识百科榜单
金融数理计算榜单
合规与风险管理榜单
投顾应用榜单
根据测评榜单,从模型等级角度看,目前仅有GPT-4 Turbo在总成绩中达到了A+的级别,国内的GLM-4与MoonShot-v1-128k等级达到A。从六类具体任务得分角度来看,各模型各类任务得分较为均衡,其中GLM-4表现较为优异,获得了一项A+、三项A与两项B,且与GPT-4 Turbo各任务等级相差较小。
测评结论指出,从金融大模型综合能力上看,国内外头部模型差距较小,体现了国内大模型在金融领域综合能力上有一定的竞争力。在本次金融测评中,依据模型表现,GLM-4位列第一梯队,其等级为A,仅低于GPT-4 Turbo,国内排名第一。从金融大模型专项能力上来看,真正实现大语言模型在金融领域的高度专业化水准仍然有一定的距离,提高金融大模型数据库质量、完善模型对于金融学问题的解释标准(尤其是依据国内标准),亦或为提升金融大模型性能的关键路径。
关于智谱AI
智谱AI致力于打造新一代认知智能大模型,专注于做大模型的中国创新。公司于2020年底研发GLM预训练架构,2021年训练完成百亿参数模型GLM-10B,同年利用MoE架构成功训练出收敛的万亿稀疏模型,2022年合作研发了中英双语千亿级超大规模预训练模型GLM-130B并开源。2023年,智谱 AI 推出千亿基座对话模型ChatGLM并两次升级,开源版本的 ChatGLM-6B 让大模型开发者的本地微调和部署成为可能,在开源社区受到广泛欢迎。
2024年1月,智谱AI推出新一代基座大模型GLM-4,整体性能相比上一代大幅提升,比肩世界先进水平。它支持更长上下文,具备更强多模态能力,推理速度更快,支持更高并发,大大降低推理成本。同时,GLM-4的智能体能力得到大幅提升,可根据用户意图,自动理解、规划指令以完成复杂任务。GLMs 个性化智能体定制功能亦同时上线,用户用简单提示词指令即能创建属于自己的 GLM 智能体,由此任何人都能实现大模型的便捷开发。
基于全自研基座大模型的强大能力,智谱 AI 构建了极具竞争力的AIGC模型产品矩阵,包括AI提效助手智谱清言、高效率代码模型CodeGeeX、多模态理解模型CogVLM和文生图模型CogView等。
践行Model as a Service市场理念,智谱AI致力于打造高效率、通用化的“模型即服务”开发新范式,通过大模型链接物理世界的亿级用户,为千行百业带来持续创新与变革,加速迈向通用人工智能的时代。
